
In a recent review, we took an in-depth look into the Wreally Transcribe software being used around Silicon Valley and in the US publishing, legal and finance industry, (they can count Uber, Airbnb, Time, CBS, KPMG and PWC among their many customers).
Rather than bloat that review with the science behind how it all works, we thought we would provide this interesting article that deep dives into current speech recognization technology, and in what way it helps make Transcribe a high-quality transcribing tool.
Table of Contents
Sound, Voice, Speech, and Voice-and-Speech Recognition Software
Sound is produced in the vocal tract, which is the cavity in the head and neck that allows for phonation to occur. The vocal tract is formed by the oral cavity (bounded by the mouth, tongue, upper palate, and teeth), nasal cavity, laryngeal cavity, and pharynx.
Physiologically, the sound is produced in the laryngeal cavity when air passes through the glottis and vibrates the vocal cords.
The glottis is the space formed between these cords and is thus a non-physical part of the voice tract.
To be more specific, the vibration of these cords produces a sound that is interpreted by the human ear as voice. If this voice is produced by moving the cords closer together so as to reduce the glottis, then it is called a glottal sound, while if the sound is produced by enlarging the glottis by moving the cords away from each other, then it is called a voiceless glottal fricative sound.
What one needs to understand is that the sound produced in the laryngeal cavity does produce resonances in the vocal tract which gives rise to a formant (which will be explained later) which can differentiate the sound made by one person from a sound made by another person.
Also, each sound is characterized by its unique set of loudness (or sound intensity) and pitch (frequency). These 2 qualities are important for voice recognition and speech recognition AI.
Even though speech and voice recognition can seem similar, they are not, and they differ fundamentally in their operation and utility. In other words, voice recognition differs from speech recognition.
Voice recognition is the identification of the speaker, not what he or she is saying (the speech), while speech recognition is the identification of the speech (not the speaker).
As expected, voice recognition is useful in a security system that can use the voice of the speaker to authenticate/verify his or her identity; while speech recognition is useful in transcription services that transcribe speech into human-readable text, the transcript.
As compared to the audio recording, this transcript is searchable and is much smaller in size, for example (e.g) the transcript can be 57 kilobytes (kB) for a 2-hour long audio recording that is 256 megabytes (MB) in size.
Moreover, the transcript can be used to generate a subtitle that is included in the video so as to complement the visual information with displayed text that transcribes the video’s audio component.
If this subtitle includes text that interpretive descriptions of non-speech elements e.g yawns, then it is called a caption.
Therefore, the transcript can be used as the base for creating a closed caption for films to be shown an audience who do not speak the language used by the actors. This means that Transcribe can be used in the film industry to create bilingual or multilingual closed captions for films.
As mentioned above, speech recognition is critical in a transcription software like Transcribe, and as expected, it is contained in the software as an algorithm set that is weaved with a programmable instruction set.
Speech Recognition System and the Transcription Software

The speech recognition engine in Transcribe allows the software to listen to and recognize a spoken language, and then translate this speech to text.
This engine is also called computer speech recognition, automatic speech recognition, and speech-to-text (STT) AI. The STT AI is at the core of any speech recognition system (SRS) used by providers of online transcription services like WReally.
If this STT AI is bundled with a media player and a text processor so that it can receive audio input via the media player, and then print out the output in the text processor, then it is called a transcription software.
However, if the STT-AI is only bundled with the media player, then it is described as a speech recognition system (SRS). Normally, the SRS must undergo a process called enrollment, which is basically a training of the speech-to-text AI.
To train this STT AI, a human speaker reads a text into the AI via a microphone, and the AI analyzes the human voice and recognizes speech sounds which are then used to create a written text that corresponds to the phonation of the human speech.
This is also used in Transcribe to familiarize the software with the accent and voice of the user. Moreover, during enrollment, recognition of speech sounds allows the AI to organize these sounds into sets, which are then used to build its phoneme base.
Each set of speech sound that distinguishes a speaker of one language from a speaker of another language is called a phoneme.
As expected, phonemes form the basis of speech accents, and recognition of phonemes allows the AI to recognize and instantly match that accent to a specific human language, as well as determine if the speaker is a native language speaker, or a person who has learned the language as a second language.
It is this quality of machine learning that gives the SRS the NLP capability, and as expected, it makes the proprietary SRS used by WReally to be classified as an HLT that can provide speech-to-text services.
The speech recognition system which requires enrollment for learning and operationalizing its STT AI is called a speaker-dependent system.
Some SRS do not require enrollment to train their AIs in speech recognition, and such an SRS is called a speaker-independent system.
For a transcription software, a speaker-dependent SRS is better than a speaker-independent system, because enrollment allows the SRS to recognize and interpret human speech, as well as collect and understand the vocabulary of the spoken language, besides storing this vocabulary in a database.
Storing the vocabulary in a database is important as it allows each of the transcribed words to be matched with their dictionary equivalents, so that misspelled words can be filtered out or corrected.
Moreover, it allows each spoken word to be compared to its corresponding dictionary pronunciation. Therefore, the SRS requires a database that has a wordbook (which stores the human [spoken] vocabulary) and a dictionary.
The sub-component of the SRS used by WReally to understand phonemes and differentiate different accents can be described as a voice-recognition AI (or VRAI).
This VRAI is a modified form of voice recognition AI that places much emphasis on the accent of the speaker, not his/her identity.
Phonemes, Formants, and more
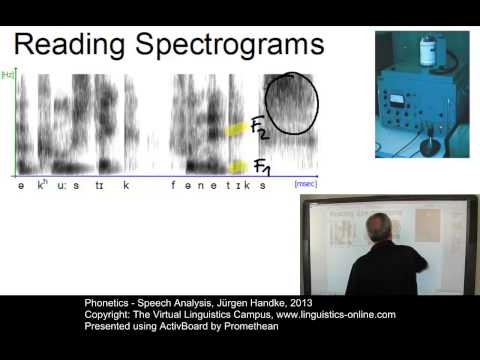
In computational linguistics, each phoneme is associated with a formant. Formant is a word coined in 1894 by Ludimar Hermann to describe the vocal properties of a vowel.
Hermann used this word to describe the acoustic resonance generated by the human vocal tract when speaking one vowel, and because this resonance is measured in terms of acoustic frequency, then each vowel can be assigned a unique range of acoustic frequencies.
This allows for the same vowel to be pronounced in bass, soprano, tenor, or any voice pitch, and for the listener to easily recognize this vowel no matter the voice pitch used.
The range of voice pitch used to pronounce a vowel (or a consonant) can be measured as a frequency range in the audible spectrum, and this frequency range is now described as the formant.
For example (e.g), p is considered a phoneme in the English language, and the different ways that a child, teenager, woman, man, and old person pronounce this phoneme falls with a narrow frequency range in the audible spectrum that can be described as the p formant.
In a speech recognition system, the formant is tied to a letter or syllable, and this means that the formant forms the basis through which the STT AI translates speech into text.
In other words, a formant is the basic unit of an utterance that an SRS can recognize as the building blocks of a word, which can then be translated into a letter, number, or syllable.
Each letter or number in the word printed by a text processor is called a character, and each character is assigned a specific string of bits called an ASCII code that can be processed by the microprocessor of the personal computer (PC).
This allows the microprocessor to work with text data, as well as allocate each character a specific data size, which is usually 1 byte.
This is because each character is assigned a string of 8 bits, and 8 bits form a byte. Therefore, if the word has 4 letters, then its size is 4bytes.
Each number is also assigned a byte, and if the word has both letters and numbers, e.g, mid-2020, then the word is designated as an alphanumeric word.
The powerful text processing software used in Transcribe can generate alphanumeric text whose size can be approximated based on the total character count (inclusive of spaces between words as each of these spaces is considered a character).
This allows Transcribe to convert large audio files into small text files. This unedited machine-generated transcript can be stored in place of the audio file, hence saving storage space in the PC.
The cloud-based SRS provided by WReally provides a voice-user interface (VUI) that allows spoken human speech to interact with AI.
This basically means that the VUI allows the human speech to be converted into a data format that can be served as an input data for the SST AI, which then processes this data using its AI algorithms so as to generate output data that is displayed as text data that is printed in a text processor, such as a notepad or word document.
As expected, this SRS must also have an inbuilt text processor for printing the text data output into a human-readable format in a text file.
Because this text processor is integrated into the app, and it allows for texts to be edited, it is called an integrated text editor.
Relatedly, for this VUI to work, there needs to be a media player that can play an audio file, as well as record human speech
As expected, this Transcribe SRS features an integrated media player, which also supports clip trimming and playback loops that allows one to replay audio sections of interest. This player also allows one to set the playback speed.
The VUI is important if one uses the dictation mode in transcribe, as it allows the voice of the user as captured by the microphone to be used to generate texts in the integrated text editor.
Inverse Filtering, UPM, and LSTM

Each speech contains spoken words and background noise, such as room noise, background conversations.
The speech also includes highly accented phonemes called sibilant (high-pitched fricative consonants e.g z in zip) and plosive (phenomes produced when the vocal tract is closed so as to produce a pulmonic sound, usually a pulmonic consonant e.g p in lip) sounds.
These background noise and exaggerated phenomes need to be filtered out before the audio data is delivered to the STT-AI.
The process of converting the spoken speech into binary data allows for the speech to be processed by speech analysis tools in the STT AI, with one of the most important tools being the linear predictive coding (LPC) tool.
In Transcribe, the LPC identifies formants in the speech, and corrects over-accented plosives and sibilants, in addition to identifying and eliminating background noise.
Thereafter, the formants are processed to generate a clear phoneme, and this process is called inverse filtering. This phoneme-rich speech is known as the residue, and it is tunneled (sent) into the STT-AI for transcription.
This process of audio signal processing uses statistical and acoustic models based on the Unified Probabilistic Model (UPM) which was developed from the Hidden Markov Model (HMM).
Both UPM and HMM are used to create a speech recognition algorithm. In 1997, the Long short-term memory (LSTM) deep learning method was developed to augment UPM-based speech recognition algorithms.
Initially, the LSTM-based algorithm underwent enrollment using large volumes of recorded audio (from big data repositories), and this allowed LTSM algorithms to power speech recognition using deep feedforward recurrent neural networks that can be hosted in the cloud.
To explain its practical utility, LSTM-augmented UPM was used by the dominant player in speech recognition technology in the early 2000s.
This was Nuance Communications which licensed its SRS software to be used by Apple Inc., in Siri, a digital assistant. In 2007, Google hired researchers from Nuance Communications to develop its speech recognition software, and this allowed Google to develop the Google Voice Search.
It is these advances in speech recognition algorithm that allowed WReally to build its own proprietary SRS engine that could be integrated with a text processor so as to create a transcription software.
Algorithms and Transcription

The process of STT transcription as done by Transcribe is supported by an algorithmic framework that allows its speech recognition engine to structure the speech into a tiered hierarchy that is set as follows:
Phonemes are identified.
Phenomes are used to build words. Probabilistic rules are used in the algorithms to recognize the spoken word. Likewise, the dictionary in its database is used to provide the spellings of the words. Words are combined to form syntactically-acceptable phrases.
Phrases are used to create sentences. Its grammar engine is used to parse this sentence, and it can dismiss syntactically-unsound sentences. This is supported by the deterministic rules of the algorithms used in the engine.
These deterministic rules are used to create the artificial neural network based on UPM, HMM, or LTSM, for computing the spectral domains of the digitized and sampled speech.
This neural network uses the Fourier transform to create frames from the speech so that each frame can be computed. A frame is basically a small time-length or segment of the speech, e.g 10 milliseconds (ms) of the speech is a considered frame.